In diesem im Mai 2022 erteilten Patent geht es darum, Korrelationen einzelner Suchbegriffe mittels des HyperLogLog Algorithmus zu bestimmen und die Suchergebnisse danach zu verbessern.
Mit dem Verfahren wird versucht, den Kontext eines Suchbegriffs besser und effizienter zu bestimmen und dementsprechend die Suchergebnisse anzupassen. Je nachdem wie nah ein Begriff / Term einer entprechenden Entität innerhalb der Hyperlog-Skizze ist, kann diesem dadurch eine höhere Gewichtung innerhalb der Suchergebnisse zugeordnet werden.
Hintergrund
Im Patent heißt es:
Die Suche nach Suchbegriffen liefert in der Regel zahlreiche Ergebnisse, die nach ihrer Relevanz geordnet werden müssen. Die Relevanz der einzelnen Ergebnisse kann auf verschiedene Weise angenähert werden.
Zum Beispiel kann ein Begriff verschiedene Bedeutungen oder Kontexte haben, die entsprechend einem gewichteten Suchindex organisiert werden können, der verschiedene Begriffe mit Suchfeldern kennzeichnet. Jeder gekennzeichnete Begriff kann ein separater Eintrag in dem gewichteten Suchindex sein und kann darüber hinaus mit einer Suchgewichtung verbunden sein, die die Anzahl der unterschiedlichen Elemente angibt, die den gekennzeichneten Begriff enthalten. Begriffe, die mit höheren Suchgewichten verbunden sind, können in den Suchergebnissen bevorzugt behandelt werden.
Der gewichtete Suchindex ermöglicht es, Begriffe nach ihren jeweiligen Bedeutungen zu klassifizieren und die Ergebnisse nach diesen Bedeutungen zu priorisieren, um relevantere Bedeutungen gegenüber weniger relevanten zu finden. Der gewichtete Suchindex ermöglicht auch die Identifizierung und Priorisierung relevanterer Suchfelder auf der Grundlage der Suchbegriffe, die mit diesen Suchfeldern verbunden sind. Dadurch wird die globale Suche über mehrere Suchfelder hinweg effizienter.
Der gewichtete Suchindex ist begrenzt. Die Relevanz der Suchergebnisse wird nur anhand der in der Suche enthaltenen Begriffe und der Korrelationen zwischen den Suchbegriffen und ihren jeweiligen Feldern angenähert. Korrelationen zwischen zwei Suchbegriffen können jedoch nicht aus dem gewichteten Suchindex abgeleitet werden, und die Speicherung von Aufzeichnungen darüber, welche Suchergebnisse welche Suchbegriffe enthalten, ist unglaublich ineffizient, insbesondere bei häufigen oder gebräuchlichen Begriffen, was den Speicherverbrauch angeht, was besonders bei großen Datenmengen unpraktisch ist.
Patentinformationen
Titel deutsch: Bestimmung dimensionaler Korrelation mit Hyperloglog
Titel englisch: Finding dimensional correlation using hyperloglog
Erfinder: Lloyd Tabb
Zessionar: Google LLC
US-Patent: 11,341,147
Eingereicht: 11.12.2020
Erteilt: 24.05.2022
Abstraktion
A method for determining overlap between search terms in distinct elements in data collected from a number of sources. The method involves receiving a first search term, accessing a first hyperloglog sketch of the first search term and a second hyperloglog sketch of a second search term, and determining a degree of overlap between the first search term and the second search term based on the first hyperloglog sketch of the first search term and a second hyperloglog sketch of a second search term. Respective hyperloglog sketches of additional search terms can be accessed, and respective degrees of overlap between the first search term and the additional search terms can be determined. Respective correlation values can be assigned based on the respective degrees of overlap. Search results can be organized according to the respective correlation values in order to prioritize search terms having higher correlation values.
Quelle: https://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&p=1&u=/netahtml/PTO/srchnum.html&r=1&f=G&l=50&d=PALL&s1=11341147.PN.
Erklärung
In der Abstraktion wird ein Verfahren zur Bestimmung der Überlappung zwischen Suchbegriffen innerhalb verschiedener Elemente erklärt. Die Daten hierfür werden dabei aus einer Reihe von Quellen gesammelt. Das Verfahren umfasst:
- Den Empfang eines ersten Suchbegriffs,
- den Zugriff auf eine erste Hyperlog-Skizze des ersten Suchbegriffs
- und eine zweite Hyperlog-Skizze eines zweiten Suchbegriffs,
- sowie die Bestimmung eines Überlappungsgrades zwischen dem ersten Suchbegriff und dem zweiten Suchbegriff auf der Grundlage der Hyperlog-Skizzen beider Suchbegriffe.
Es kann auch auf entsprechende Hyperlog-Skizzen weiterer Suchbegriffe zugegriffen werden, und es können entsprechende Überlappungsgrade zwischen dem ersten Suchbegriff und den weiteren Suchbegriffen ermittelt werden. Basierend auf den jeweiligen Überschneidungsgraden können Korrelationswerte zugewiesen werden. Die Suchergebnisse können nach den jeweiligen Korrelationswerten geordnet werden, um Suchbegriffe mit höheren Korrelationswerten zu priorisieren.
Erklärung der Figuren
Figur 1
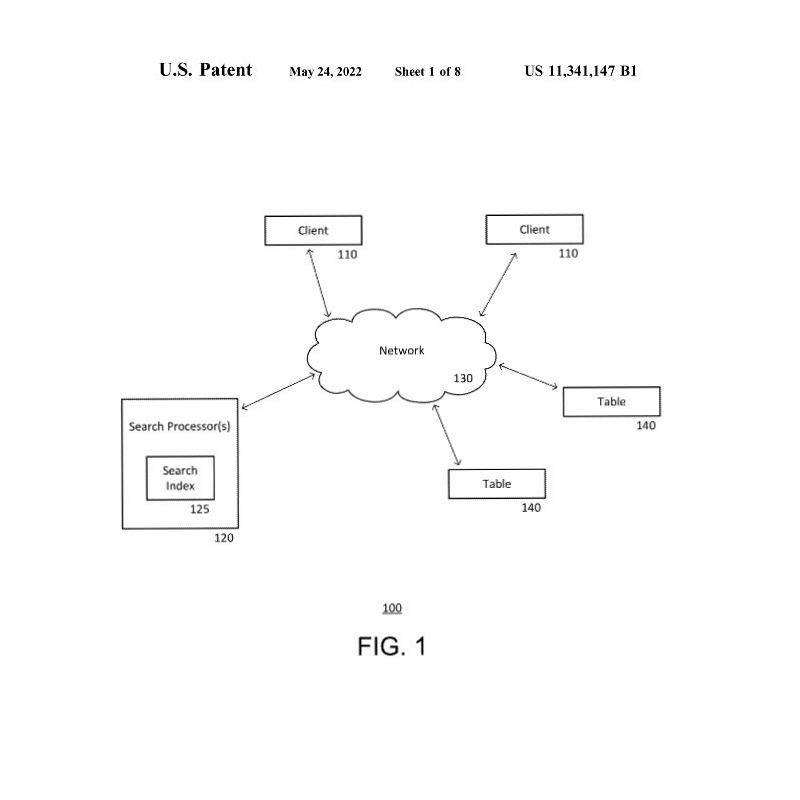
FIG. 1 zeigt ein Beispiel für ein Kommunikationsnetz 100 mit einem oder mehreren Knotenpunkten. Die Knoten können verschiedene Datenverarbeitungsgeräte darstellen, die über eine Netzwerkverbindung miteinander verbunden sind. Im Beispiel von Fig. 1 sind ein Nutzer-Knoten 110 und ein Suchprozessor-Knoten 120 dargestellt, die über eine Netzwerkverbindung 130 verbunden sind. Weitere Tabellenknoten 140, die Daten im gesamten Kommunikationsnetz 100 speichern, sind ebenfalls dargestellt. Jeder der Knoten 110, 120, 140 kann einen entsprechenden Prozessor, einen Speicher und eine Kommunikationsvorrichtung für den Empfang von Eingaben und die Übertragung von Ausgaben umfassen.
Im Betrieb kann ein Client-Knoten 110 eine Anfrage an den Suchprozessor 120 übermitteln. Die Anfrage kann einen oder mehrere Suchbegriffe enthalten, um die Anfrage des Client-Knotens 110 zu charakterisieren. Der Suchprozessor 120 kann einen Suchindex 125 enthalten, der Tabellen von anderen Knoten 120 des Kommunikationsnetzes 100 kombiniert, um Informationen über potenzielle Suchbegriffe zu liefern, die in der Anfrage gefunden werden können. Unter Verwendung der gesammelten Informationen im Suchindex 125 kann der Suchprozessor Suchergebnisse, die für die empfangene Abfrage relevant sind, an den Client zurücksenden.
Ein Beispiel für einen Suchindex wird hier in Verbindung mit FIG. 3 näher beschrieben.
Figur 2
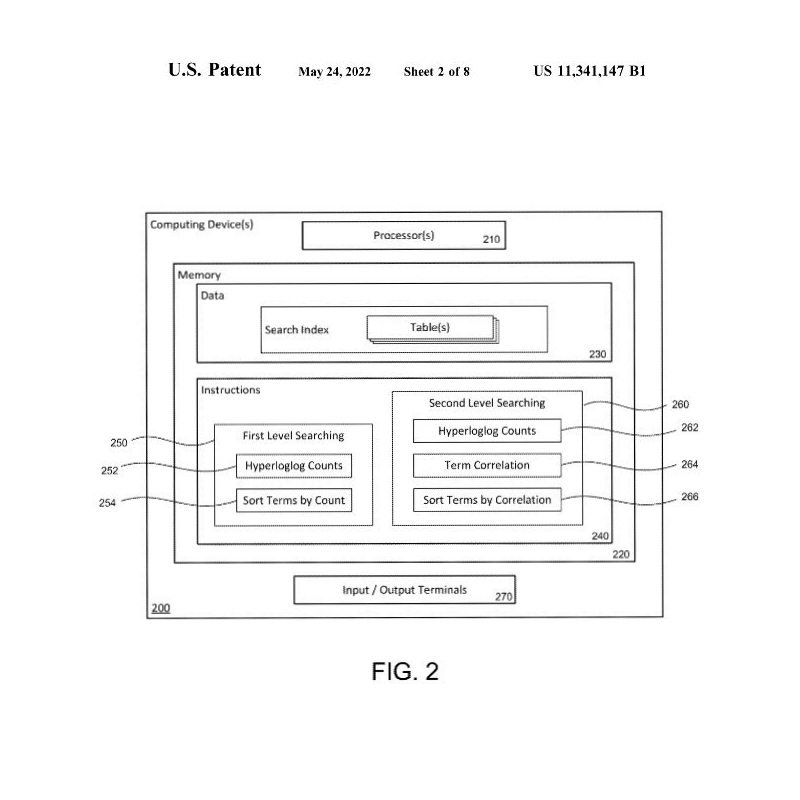
In FIG. 2 wird ein Prozessbeispiel innerhalb eines Abfrageverarbeitungssystems 200 dargestellt. Das System 200 von FIG. 2 zeigt dabei das Verfahren, welches in FIG. 1 im Knoten 120 abgebildet ist. Das Verfahren kann so konfiguriert sein, dass es Suchergebnisse als Antwort auf empfangene Anfragen aus Nutzer-Knoten (z. B. Knoten 110 von FIG. 1) zurückgibt.
FIG. 2 zeigt zudem, dass innerhalb des Verfahrens mit einem Speicher 220 gearbeitet wird, welcher Daten 230 in Tabellen innerhalb eines eigenen Suchindex speichert. Ein Beispiel dieser Tabellen wird in FIG. 3 beschrieben.
Mittels der Suchroutine 250 auf erster Ebene werden kategorisierte Suchbegriffe aus einer Tabelle (siehe FIG. 3) identifiziert, die für die Anfrage eines Nutzers am relevantesten sind. In der zweiten Suchroutine 260 werden anschließend Suchbegriffe identifiziert, die am stärksten mit den Ergebnissen der ersten Suchroutine korrelieren. Dies kann bei Bedarf auch wiederkehrend (iterativ) durchgeführt werden, um genauere Ergebnisse zu erzielen.
Auf erster Ebene 250 wird mit einer Hyperlog-Zählroutine 252 gearbeitet, welche die Hyperlog-Zahl für jeden im Suchindex enthaltenen Suchbegriff bestimmt, der mit einem Begriff der Abfrage übereinstimmt, sowie eine Sortierroutine 254, die die Suchbegriffe nach ihren jeweiligen Hyperlog-Zahlen sortiert. Dies wird gemacht, um in der Ausgabe einen hohen Relevanzwert für die Suchabfrage eines Nutzers zu erzielen. Wenn eine empfangene Abfrage den Begriff „Phoenix“ enthält, kann es unklar sein, ob der Nutzer nach Flügen suchen wollte, die von Phoenix ausgehen oder in Phoenix ankommen, wie im Beispiel von FIG. 3. Bei der Suche auf der ersten Ebene wird daher die Hyperlog-Verarbeitung und die anschließende Zählung genutzt, um die jeweiligen Suchgewichte der Suchwerte „Phoenix“ als Abflugort und „Phoenix“ als Zielort zu bestimmen. In FIG. 3 wird gezeigt, dass der Herkunftsort „Phoenix“ (flight_origin) ein viel höheres Suchgewicht hat als das Flugziel „Phoenix“ (flight_destination). Daher werden Suchergebnisse, die den Herkunftsort „Phoenix“ enthalten, gegenüber Suchergebnissen, die das Flugziel „Phoenix“ enthalten, bevorzugt.
In der Suche auf der zweiten Ebene 260 wird mit einer Zählroutine 262 gearbeitet, die die Hyperlog-Zahl der in den Suchindex aufgenommenen Suchbegriffe bestimmt, die möglicherweise mit einem auf erster Ebene 250 identifizierten Suchbegriff korrelieren. Hierbei wird in einer Routine zur Bestimmung der Termkorrelation 264 gearbeitet, die für jeden Suchbegriff einen Korrelationsgrad zwischen dem Begriff der ersten Ebene und dem Suchbegriff bestimmt. Anschließend werden mit einer Sortierroutine 266 die Suchbegriffe nach ihren jeweiligen Korrelationsgraden zum Suchbegriff der ersten Ebene sortiert. Mit diesem Vorgehen kann der Suchprozessor Ergebnisse zurückgeben, die Suchbegriffe enthalten, die wahrscheinlich für die verarbeitete Anfrage relevant sind, selbst wenn diese Begriffe selbst nicht in der Anfrage enthalten sind.
Es können also Begriffe aufgrund ihrer starken Korrelation mit anderen in der Anfrage enthaltenen Begriffen als relevant eingestuft werden. Auch können die Suchergebnisse auf der Grundlage der auf zweiter Ebene abgeleiteten Korrelationen geordnet werden. Wenn z. B. eine empfangene Abfrage den Begriff „Phoenix“ (eine amerikanische Stadt) enthält und viele der Flüge, die in Phoenix ankommen und von dort abfliegen, von Delta (Delta ist eine amerikanische Fluggesellschaft) bedient werden, dann kann es in den Daten eine starke Korrelation zwischen „Phoenix“ und „Delta“ geben.
Figur 3.

In FIG. 3 wird ein Beispiel für eine Suchindex-Tabelle 300 dargestellt. Die Suchindex-Tabelle wird bereits in FIG. 1 und FIG. 2 erwähnt.
In dem Beispiel der Tabelle 300 beziehen sich die gesammelten Daten auf Fluginformationen. Die Fluginformationen können dabei aus verschiedenen Tabellen gesammelt werden, die im gesamten Kommunikationsnetz 100 aus FIG. 1 gespeichert sind. Zum Beispiel kann jede der verschiedenen Tabellen eine entsprechende Liste von Flügen enthalten. Auch Informationen über jeden Flug, wie z. B. der Start- und Zielort und die Fluggesellschaft jedes Fluges können angegeben werden. Jedem Flug kann außerdem ein eindeutiger Schlüssel oder eine andere Form der Identifizierung zugeordnet werden, die den Flug von anderen Flügen unterscheidet. Der Suchindex kann auf der Grundlage aller Fluginformationen in diesen ferngespeicherten Tabellen erstellt werden, ohne jedoch alle Fluginformationen aus den ferngespeicherten Tabellen zu berücksichtigen.
Spalte 1 „Suchwert“ 310
In dem Beispiel enthält die erste Spalte die im Suchindex gespeicherten Suchbegriffe. Wie in FIG. 3 dargestellt, handelt es sich bei den Suchbegriffen um die aus den Tabellen gesammelten Informationen, einschließlich der verschiedenen Abflugorte, Flugziele und Fluggesellschaften. Im Beispiel der Suchindex-Tabelle 300 umfassen diese Suchbegriffe oder Suchwerte „Phoenix“, „Albuquerque“, „Denver“ etc. Bei den Suchbegriffen in FIG. 3 handelt es sich um Werte, die durch alphanumerische Zeichenfolgen gekennzeichnet sind, obwohl stattdessen auch jede andere Art von Wert und jedes andere Format verwendet werden kann.
Es ist auch zu erkennen, dass die erste Spalte 310 die Suchbegriffe nicht nur nach ihren Werten sortiert, da derselbe Suchbegriff in mehr als einer Zeile der ersten Spalte 310 erscheinen kann. So erscheint beispielsweise der Wert „Phoenix“ sowohl in Zeile 1 als auch in Zeile 8. Dies liegt daran, dass die Suchbegriffe nach ihren jeweiligen Kategorien geordnet sind, so dass der Abflugort „Phoenix“ im Suchindex getrennt von dem Zielort „Phoenix“ aufgeführt wird. Es ist also zu erkennen, dass die Suchbegriffe im Suchindex kategorisierte Begriffe sind, die durch eine Kombination aus Wert und Suchfeld organisiert sind.
Spalte 2 „Suchfeld“ 320
Eine zweite Spalte kennzeichnet die jeweiligen Kategorien oder Felder der in der ersten Spalte 310 enthaltenen Suchbegriffe. Wie im Beispiel von FIG. 3 sind einige der eingegebenen Werte, wie z. B. „Phoenix“ in Zeile 1, Abflugorte, und diese Werte sind durch das Suchfeld „flight_origin“ in der entsprechenden zweiten Spalte 320 gekennzeichnet. Andere Werte in der ersten Spalte 310, wie z. B. „Denver“ in Zeile 3, sind Zielorte, und diese Werte sind durch das Suchfeld „flight_destination“ in der entsprechenden zweiten Spalte 320 gekennzeichnet. Andere Werte in der ersten Spalte 310, wie z. B. „Delta“ in Zeile 9, sind Fluggesellschaften, und diese Werte sind durch das Suchfeld „flight_carrier“ in der entsprechenden zweiten Spalte 320 gekennzeichnet. Start, Flugziel und Flugträger sind nur einige Beispiele für mögliche Kategorien oder Suchfelder, und es versteht sich, dass diese Kategorien in anderen Beispielen durch andere für Fluginformationen relevante Kategorien ergänzt oder ersetzt werden können.
Spalte 3 „Suchgewicht“ 330
Die dritte Spalte enthält Werte, die einen Hinweis darauf geben, wie wahrscheinlich es ist, dass sich eine Anfrage auf den zugehörigen Suchbegriff bezieht, im Gegensatz zu einem anderen Suchbegriff. Die Verwendung der eindeutigen Schlüssel, im Gegensatz zur Zählung der Anzahl der am Knoten des Suchindexes eingegangenen Einträge, stellt sicher, dass ein bestimmter Flug im Suchindex nicht doppelt gezählt wird, selbst wenn Duplikate dieses Fluges in mehreren ferngespeicherten Tabellen der entfernten Knoten gespeichert sind.
Spalte 4 „Hyperlog-Skizze“ 340
Die vierte Spalte enthält eine alphanumerisch kodierte Hyperlog-Skizze des kategorisierten Suchbegriffs. Die Hyperlog-Skizze umfasst eine vorgegebene Anzahl von Registern oder Spalten, von denen jedes eine vorgegebene Anzahl von Bits hat.
Der Vorteil der Hyperlog-Skizze besteht für Google darin, dass sie einen guten Näherungswert für die Anzahl der eindeutigen Schlüssel liefert, die mit dem gegebenen kategorisierten Suchbegriff verbunden sind, ohne dass ein inhärenter Fehler aufgrund des Empfangs doppelter Einträge desselben Datenteils aus verschiedenen entfernten Quellen entsteht.
In einigen Beispielen kann die Anzahl der eindeutigen Einträge, die in der dritten Spalte 330 angezeigt werden, durch Verarbeitung der entsprechenden Hyperlog-Skizze der vierten Spalte 340 abgeleitet werden.
Figur 4., 5. und 6.
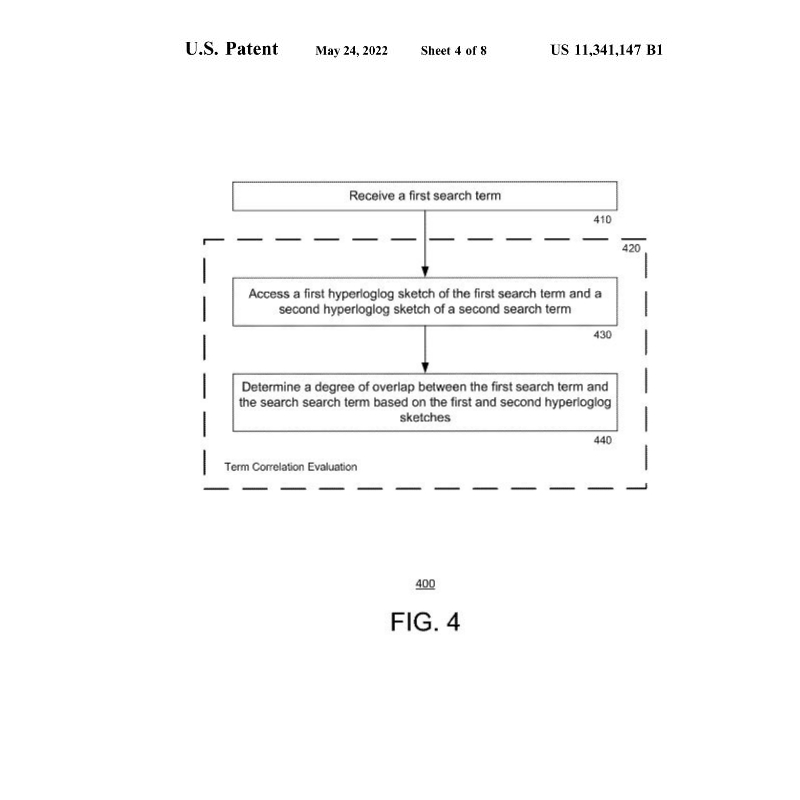
In FIG. 4, FIG. 5 und FIG. 6 wird der Prozess in der ersten und zweiten Ebene aus FIG. 2 mit einem Flussdiagramm beschrieben.
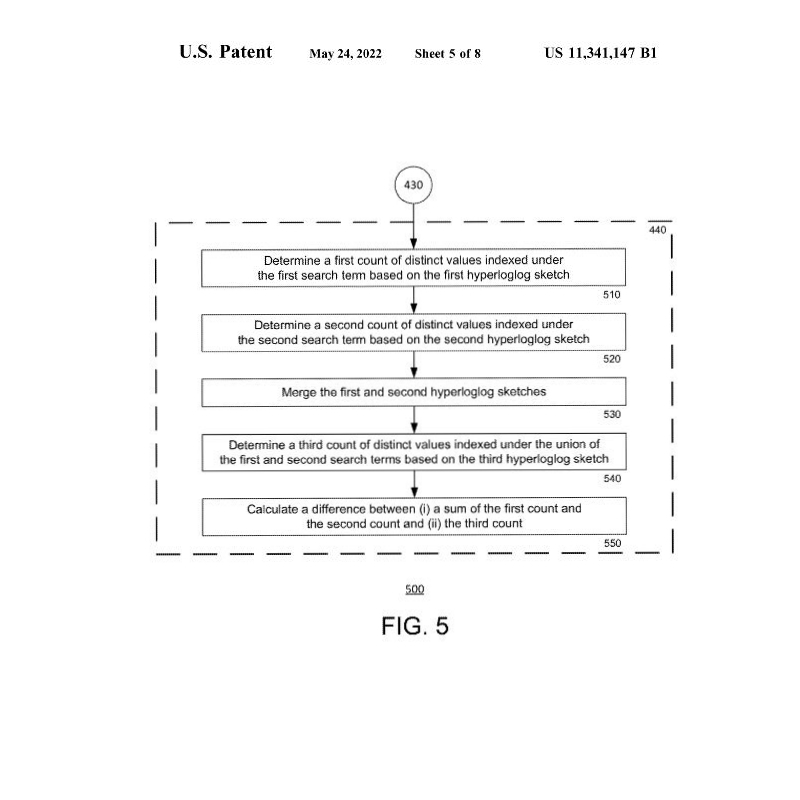
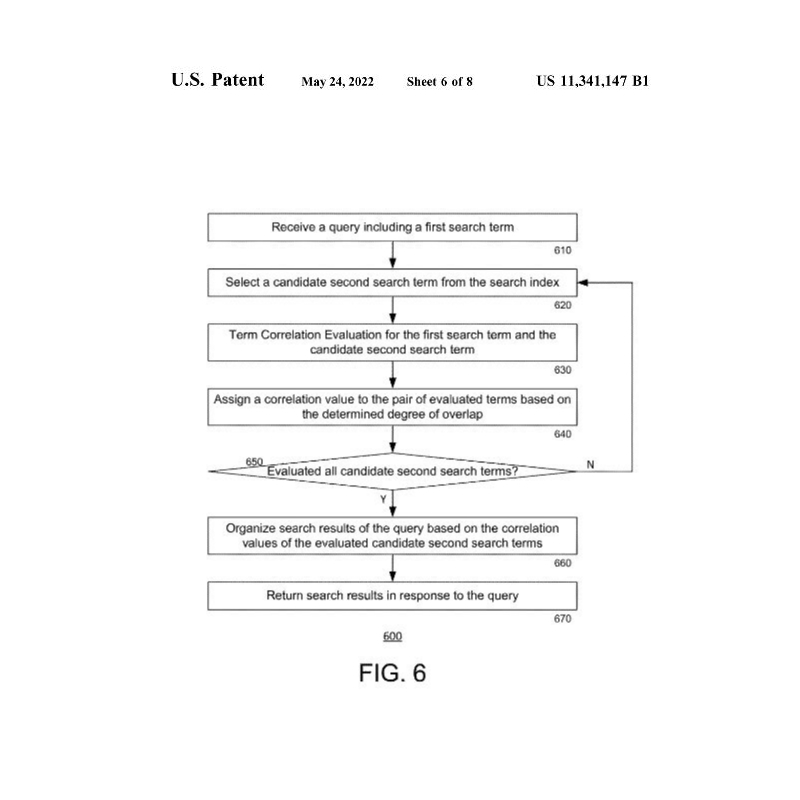
Die Prozesse der FIG. 4, FIG. 5 und FIG. 6 beziehen sich im Allgemeinen auf die Bewertung der Korrelation zwischen den jeweiligen Suchbegriffen. In diesem Zusammenhang kann ein „Suchbegriff“ dasselbe sein wie ein Suchwert (siehe FIG. 3), was bedeutet, dass die Anfrage ein Wort enthält und die Suchergebnisse andere Wörter, die stark mit dem gesuchten Wort korreliert sind, gegenüber anderen Wörtern, die schwach mit dem Suchwort korreliert sind, bevorzugen. Darüber hinaus kann in einigen Beispielen der Suchbegriff ein kategorisierter Suchbegriff sein, der sowohl einen Suchwert als auch ein Suchfeld hat, wie im Suchindex von FIG. 3 dargestellt. In dieser Hinsicht kann der Suchroutine 600 der zweiten Ebene von FIG. 6 eine Suchroutine der ersten Ebene vorausgehen, wie bereits in FIG. 2 beschrieben wurde.
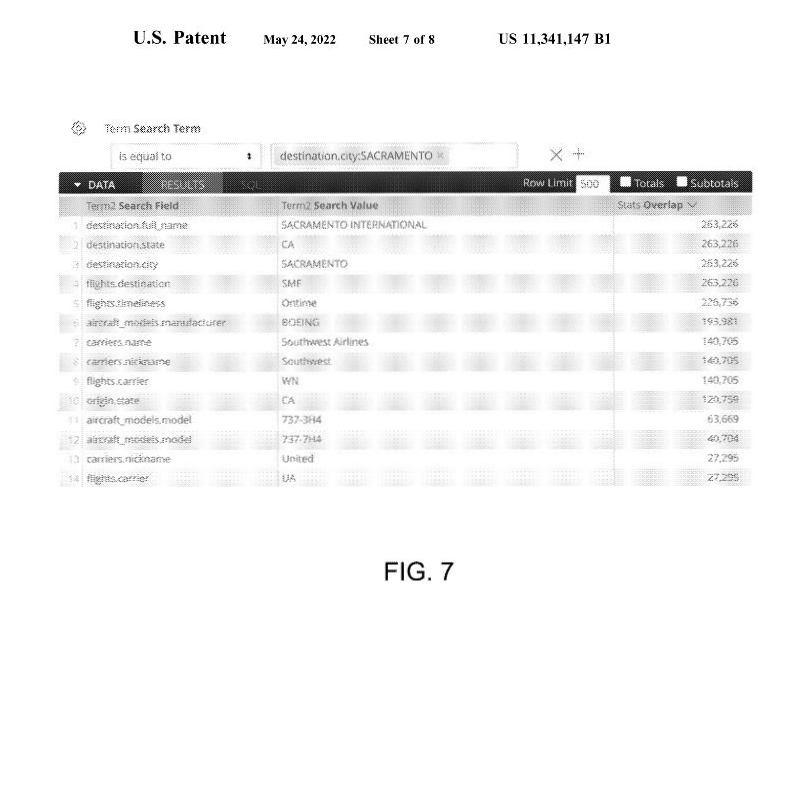
Zur besseren Darstellung zeigen FIG. 7 und FIG. 8 beispielhafte, nach Rangfolge geordnete Bewertungsergebnisse einer Suchtechnik der zweiten Ebene. Im Beispiel von FIG. 7 wurde eine Suche in der NTSB (eine Datenbank mit Flugdaten https://de.wikipedia.org/wiki/National_Transportation_Safety_Board) durchgeführt, und der angegebene Suchbegriff war „Flugziel Sacramento“, was bedeutet, dass die Suche sowohl den Suchwert „Sacramento“ als auch das Suchfeld „destination“ (Flugziel) angibt. Die Ergebnisse der Suche auf der zweiten Ebene zeigen andere charakterisierte Begriffe, die eine starke Überschneidung mit dem Suchbegriff „Sacramento“ aufweisen, der als Zielstadt kategorisiert ist. Zu den Begriffen, die sich zu 100 % überschneiden, gehören „SACRAMENTO INTERNATIONAL“ (destination.full_name), „CA“ (destination.state) und „SMF“ (flights.destination), da alle Flüge, die in der Stadt Sacramento ankommen, auch in Sacramento International und in Kalifornien ankommen. Andere Begriffe, die eine hohe Korrelation aufweisen, sind „Ontime“ (flight.timeliness) und „BOEING“ (aircraft_models.manufacturer), was bedeutet, dass die meisten Flüge nach Sacramento, die in den ferngespeicherten Tabellen eingetragen sind, darauf hindeuten, dass der Flugzeughersteller Boeing ist und dass der Flug pünktlich ist oder war.

Im Beispiel von FIG. 8 wurde eine Suche in der Datenbank „IMDb“ (eine Online-Filmdatenbank: https://en.wikipedia.org/wiki/IMDb) nach „batman“ durchgeführt, wobei kein Suchfeld vorgesehen war. Die Ergebnisse zeigen, dass die meisten Einträge in IMDb, die „batman“ enthalten, „Batman“ als Name einer Filmfigur angeben. Die Ergebnisse zeigen auch, dass Einträge, die „Batman“ enthalten, in der Regel auch einen „TV-Episode“-Titel mit den für Fernseh-Episoden typischen Rollen enthalten. Ebenfalls ist zu sehen, dass Einträge, die „Batman“ enthalten, typischerweise auch Figuren namens „Bruce Wayne“ und „Robin“ enthalten, was auf eine starke Korrelation zum Term „batman“ schließen lässt.
Die in FIG. 7 und FIG. 8 dargestellten Ergebnisse können zur Priorisierung von Suchergebnissen verwendet werden. Die Informationen über Überschneidungen können verwendet werden, um abzuleiten, an welchen anderen Begriffen ein abfragender Nutzer interessiert sein könnte. Die an den Nutzer zurückgegebenen Suchergebnisse können anschließend so sortiert oder organisiert werden, um Einträge zu bevorzugen, die diese abgeleiteten Begriffe enthalten.
Quellen & Weblinks
Link: https://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&p=1&u=/netahtml/PTO/srchnum.html&r=1&f=G&l=50&d=PALL&s1=11341147.PN.
Link: https://patents.justia.com/patent/11341147
Link: https://cloud.google.com/bigquery/docs/reference/standard-sql/hll_functions
Link: https://research.google/pubs/pub40671/
Link zu FIG. 7: https://www.ntsb.gov/Pages/home.aspx
Link zu FIG. 8: https://www.imdb.com/

Seit 2016 ist Rainer bei einer der führenden SEO-Agenturen im Bereich SEO-OnPage und Webanalyse tätig. Zu seinen Fachgebieten zählen strategische, analytische und technische SEO-Arbeiten. Seit 2017 ist er unter anderem Referent für den Händlerbund, die Google Zukunftswerkstatt in München und verantwortet seit 2018 zudem die Abteilung SEO-OnPage innerhalb der Agentur.